retrieval-augmented generation

What is retrieval-augmented generation?
Retrieval-augmented generation (RAG) is an artificial intelligence (AI) framework that retrieves data from external sources of knowledge to improve the quality of responses. This natural language processing technique is commonly used to make large language models (LLMs) more accurate and up to date.
LLMs are AI models that power chatbots such as OpenAI's ChatGPT and Google Bard. LLMs can understand, summarize, generate and predict new content. However, they can still be inconsistent and fail at some knowledge-intensive tasks -- especially tasks that are outside their initial training data or those that require up-to-date information and transparency about how they make their decisions. When this happens, the LLM can return false information, also known as an AI hallucination.
By retrieving information from external sources when the LLM's trained data isn't enough, the quality of LLM responses improves. Retrieving information from an online source, for example, enables the LLM to access current information that it wasn't initially trained on.
What does RAG do?
LLMs are commonly trained offline, making the model uncertain of any data that's created after the model was trained. RAG is used to retrieve data from outside the LLM, which then augments the user's prompts by adding relevant retrieved data in its response.
This article is part of
What is generative AI? Everything you need to know
This process helps reduce any apparent knowledge gaps and AI hallucinations. This can be important in fields that require as much up-to-date and accurate information as possible, such as healthcare.
For more information on generative AI-related terms, read the following articles:
What is the Fréchet Inception Distance (FID)?
How to use RAG with LLMs
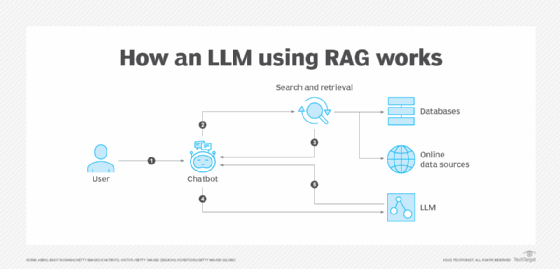
RAG combines information retrieval with a text generator model. External knowledge can be retrieved from data sources, online sources, application programming interfaces, databases or document repositories.
Using the example of a chatbot, once a user inputs a prompt, RAG summarizes that prompt using keywords or semantic data. The converted data is then sent to a search platform to retrieve the requested data, which is then sorted through based on relevancy.
The LLM then synthesizes the retrieved data with the augmented prompt and its internal training data to create a generated response that can be passed to the chatbot with sourced links for the user.
What are the benefits of RAG?
Benefits of a RAG model include the following:
- Provides current information. RAG pulls information from relevant, reliable and up-to-date sources.
- Increases user trust. Users can access the model's sources, which promotes transparency and trust in the content and lets users verify its accuracy.
- Reduces AI hallucinations. Because LLMs are grounded to external data, the model has less of a chance to make up or return incorrect information.
- Reduces computational and financial costs. Organizations don't have to spend time and resources to continuously train the model on new data.
- Synthesizes information. RAG synthesizes data by combining relevant information from retrieval and generative models to produce a response.
- Easier to train. Because RAG uses retrieved knowledge sources, the need to train the LLM on a massive amount of training data is reduced.
- Can be used for multiple tasks. Aside from chatbots, RAG can be fine-tuned for a variety of specific use cases, such as text summarization and dialogue systems.
Learn more about generative AI models, such as VAEs, GANs, diffusion, transformers and NeRFs.
Continue Reading About retrieval-augmented generation
Dig Deeper on AI technologies
-
![]()
Singapore to develop Southeast Asia’s first large language model
By: Aaron Tan
-
![]()
AWS re:Invent 2023 - Day two keynote, Dr Swami
By: Adrian Bridgwater
-
![]()
LLM series - What developers need to know about Large Language Models?
By: Adrian Bridgwater
-
![]()
Enterprise IT shops more likely to buy GenAI than build it
By: Antone Gonsalves



